diff --git a/README.md b/README.md
index e69de29..4878bb1 100644
--- a/README.md
+++ b/README.md
@@ -0,0 +1,3 @@
+
+## GIT 操作相关
+* [使用 rebase 打造可读的 git graph](git/rebase.md)
diff --git a/git/rebase.md b/git/rebase.md
new file mode 100644
index 0000000..65f1d6e
--- /dev/null
+++ b/git/rebase.md
@@ -0,0 +1,205 @@
+使用 rebase 打造可读的 git graph
+===
+
+## git graph 可读指什么?
+
+这里的可读,主要指的是能够通过看git graph了解每一次版本更迭,每一次hotfix的修改记录.反映到分支上面,有两个要求:
+
+* 每个分支的历史修改可读(单个分支的层面)
+* 每个分支的分叉合并可读(多个分支的层面)
+
+## rebase是什么,它是更优雅的merge吗?
+
+rebase翻译做`变(re)基(base)`.
+
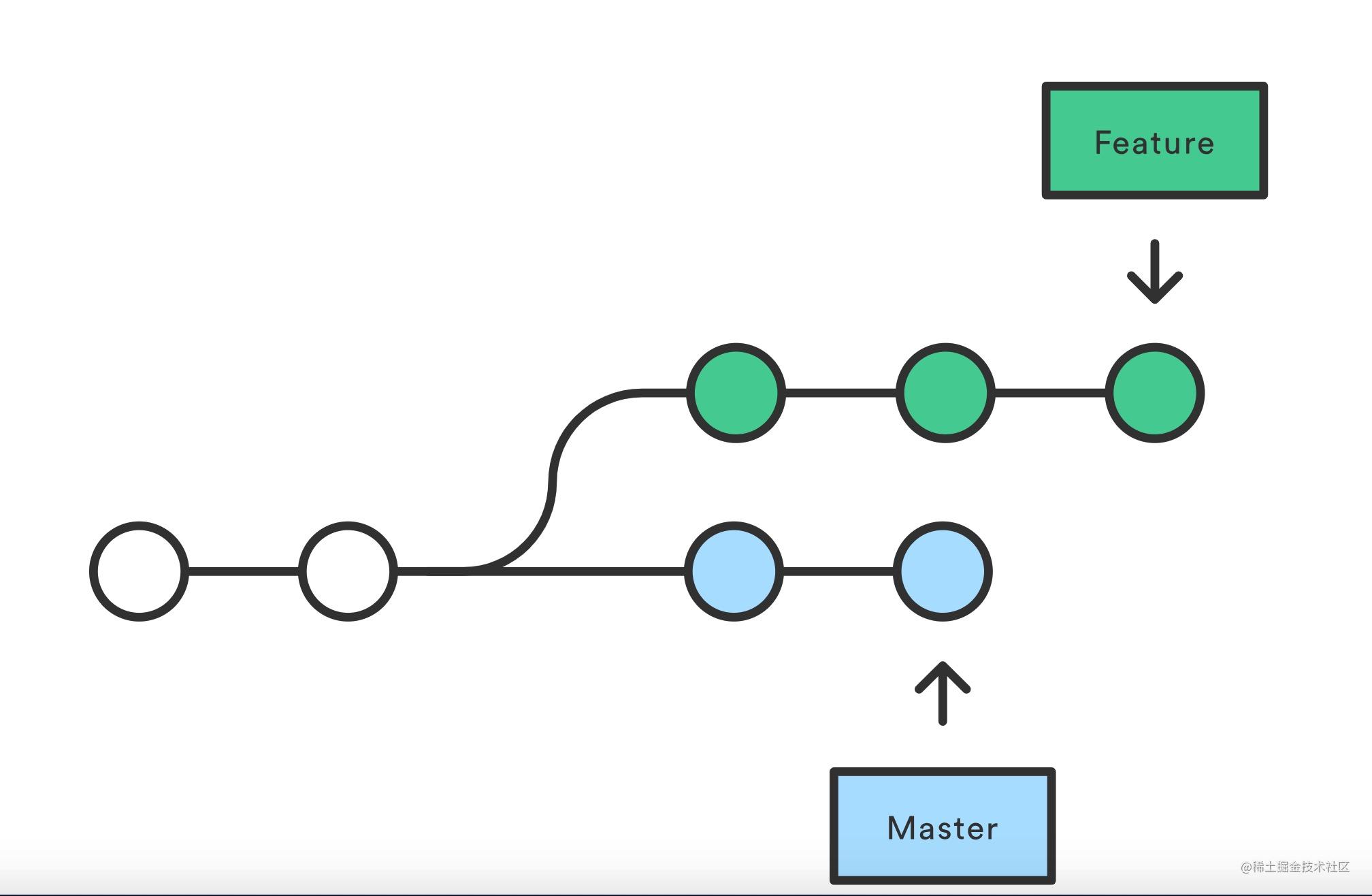
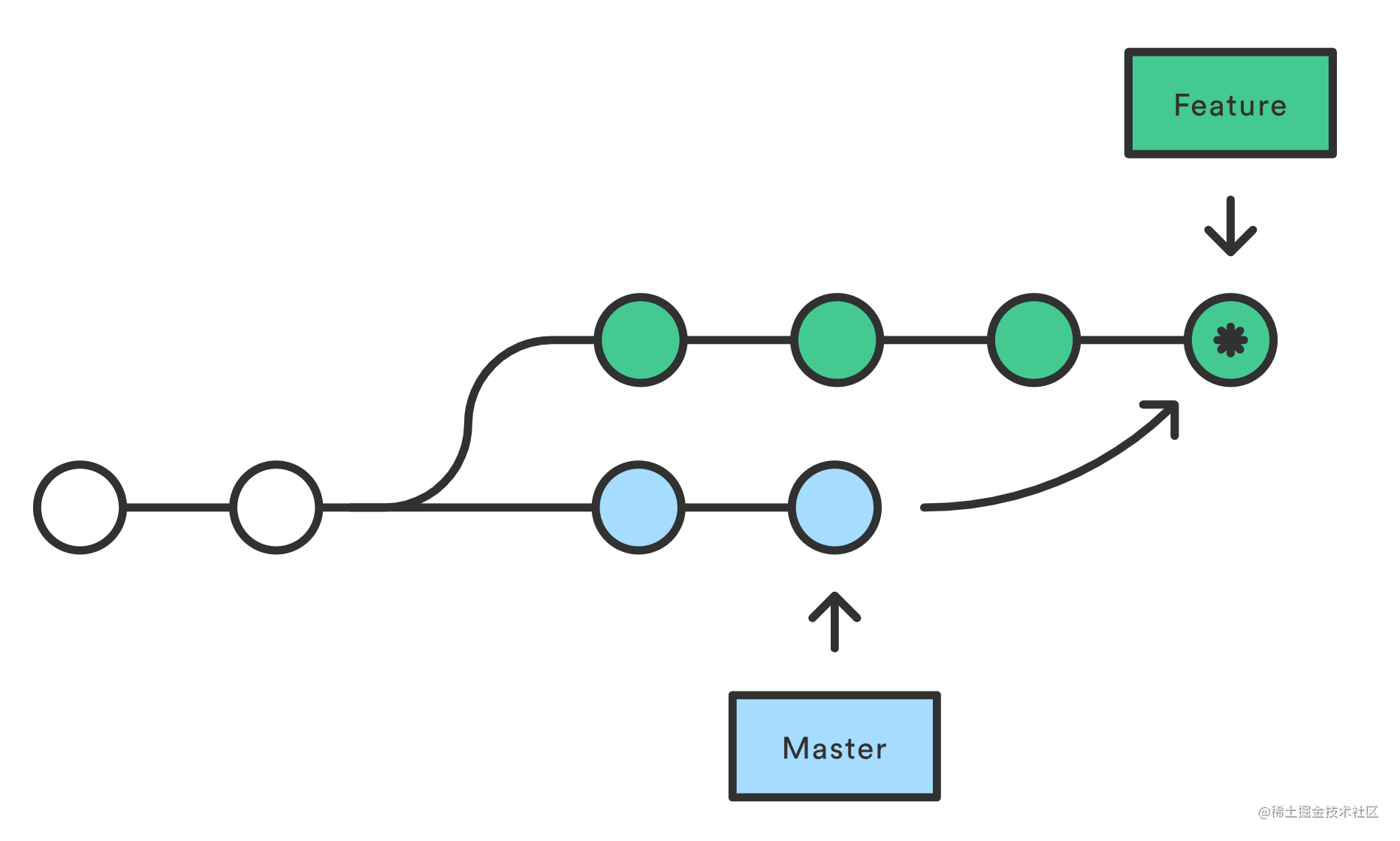
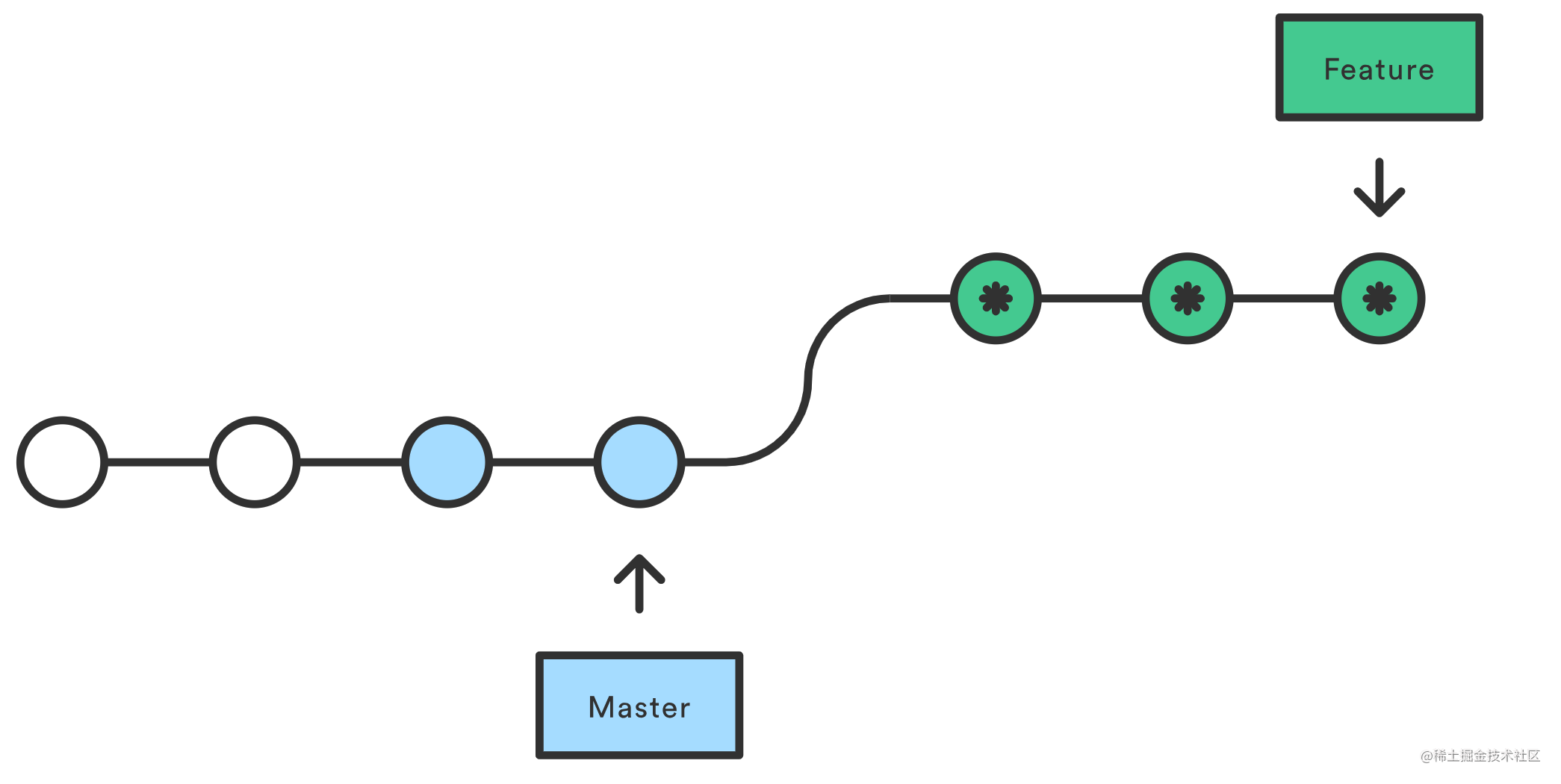
+讲rebase的文章经常会引用三张图:
+
+
+
+
+
+
+
+原本的两个分支
+
+
+
+
+
+
+
+通过merge的结果
+
+
+
+
+
+
+
+通过rebase的结果
+
+用来说明git rebase和git merge的区别的时候确实是足够了,但是 git rabase的用途并非是合并分支,它与merge根本不是同样的性质.(注意,这里的说法是`并非是`,不是`并非只是`,因为虽然有时rebase替代了merge的工作,但其原理和性质完全不一样.)
+
+rebase还有以下几种用处:
+
+* `git pull —-rebase`处理同一分支上的冲突(如果你能理解其实这是`git fetch&&git rebase`两个操作,并且理解远程分支和本地分支的区分的话,那么其实他跟单纯的rebase用法没什么区别,但是因为其场景不一样,所以单独拆分出来讲)
+* `git rebase -i`修改commit记录
+
+实质上:
+
+* merge是对目前分叉的两条分支的合并
+* rebase是对`当前分支`记录基于任何`commit节点`(不限于当前分支上的节点)的变更.
+
+rebase的`base`不能理解为分叉的基点,而是整个git库中存在的所有commit节点:
+
+* 在`git pull —-rebase`的时候,这个`当前分支`是本地分支,`commit节点`是远程分支的head
+* 在`git rebase master`的时候,这个`当前分支`是feature分支,`commit`节点是master分支的head
+* 在`git rebase -i`的时候,这个`当前分支`就是当前工作分支,`commit节点`是在 -i后注明的commit
+
+## rebase是怎么工作的?
+
+上面我们已经说到了:
+
+> `rebase`是对`当前分支`记录基于任何`commit节点`(不限于当前分支上的节点)的变更.
+
+怎么做到呢?我没有深入研究它真的是如何实现的,以下步骤一定是不对的,但足够让你理解rebase干了什么.
+
+我们标注出了两个重点,`当前分支`和`commit节点`.
+
+* 把`当前分支`branch-A从头到尾列出来,从数据结构的角度来说这是一个链表
+* 把`commit节点`所在的分支branch-B从头到尾列出来,同样是一个链表
+* 找到这两个链表最近相同的节点n
+* 把A在n之后的所有节点拆下来构成L
+* 把B在n之后的所有节点中存在的diff信息都汇总起来构成d
+* 对于L中的每一个节点,把他的diff信息拿出来,看看d中有没有冲突,如果有没法自动处理的冲突抛出错误,等待用户自己处理
+* 可选地,对于`rebase -i`来说,还可以一次取多个节点或者按照不同顺序取,你有更大的处理自由
+* 没冲突和处理完冲突的节点,改一个hash放到branch-B的`commit节点`之后 你可以把之前我们说到的三种rebase用处套在以上步骤看看,是否能够理解.
+
+## rebase很危险对吗?
+
+对,很危险.
+
+不过就像小马过河一样,光听别人说是没用的,我们需要明白为什么有人说危险,有人说不危险.我看到很多文章说rebase有问题,但他们的说法其实并不让人信服,很多时候只是他们不会用.
+
+很多人听说过一个golden rule,在文末有链接,但是很少有人会明白真正的原因.让我们一层层地剖析:
+
+* 其他人git push的时候会对比较本地分支和远程分支的区别,把不同的地方推上去
+* 如果远程分支被修改了,那么其他人的本地分支和远程分支就会出现分叉(另外还可能造成其他人之前已经推送的工作被覆盖)
+* 当出现分叉的时候,意味着其他人需要处理冲突,也就是说,你对于远程历史记录的修改使得`冲突扩散到了其他人身上`
+* 所以我们尽量不能修改远程分支,不能`把别人fetch回去的改掉`,因为他们的工作就是基于fetch回去的分支开展的(往前推进是必须的,其实也修改了远程分支,所以才会merge产生冲突,但是这个冲突是无法避免的)
+* 针对上面说的这一条,git也做了限制,如果你触犯了上面的原则,会在push的时候被阻挡,但是通过加一个`-f`可以强推
+
+实际上不止rebase这样,任何修改远程分支历史的操作都会造成冲突,并且这个冲突需要所有人都解决一遍.
+
+但是分析还是太长了,记不住怎么办?
+
+只需要记住`-f`,只要你不使用`-f`,那么就是安全的.
+
+不过仅是安全,并不能保证优雅,如果要使git graph可读,那你还得多想想:
+
+* 怎么让自己的commit历史清晰(每个commit反应了一个单位的工作,前后顺序合理)
+* 怎么让每次hotfix和feature所做的工作和顺序清晰
+
+## rebase如何让git graph可读?
+
+我们还是说回之前提到的三个用法:
+
+### git rebase master
+
+在把分支合并回master的时候,用`git rebase master`代替`git merge master`.(注意,只在合并之前使用,否则多人协作会遇到冲突)
+
+这样的好处有两个:
+
+* log里不会出现一个`Merge branch 'master' into hotfix/xxx`的节点
+* master分支上在这次merge之前已经被提交的`上一次工作`和这一次工作的顺序更清晰,因为rebase会让这次feature的分叉节点改到上一次工作后.对于master分支来说,我们并不关心checkout新的feature的顺序,我们`更关心merge新的feature的顺序`.
+
+
+
+
+
+
+
+比如这里,使用merge master导致的紫色的分叉在提交之前与master多了一次连接,而且主线上在紫色分叉合并之前还经历了一次合并,这个时间顺序并不清晰.
+
+那么在master分支上合并也用rebase吗?不是.因为我们需要master上的分叉让我们更明白master上的改变(所以使用-no-ff).实际上,不管你采用任何git flow模型,我都建议你对不太重要的分支合并采用rebase,对重要的分支合并采用merge.这样会让主干的更改更清晰,而分支不会扩散地太远.
+
+### git pull —-rebase
+
+多人在同一分支上工作的时候(包含master分支和多人合作的feature等分支),在git pull的时候会遇到冲突,git pull的默认行为是`git fetch&git merge`,merge的对象是远程分支和本地分支.
+
+它的好处基本上与上一条无异,还多了一条:
+
+* 使用merge行为的pull会将其他人的工作作为外来的分叉,从而在graph上产生一个新的分叉, 并且其他人这一段时间所做的所有的工作都会在graph上被抬升出去,如果这段时间其他人做的工作很多,graph的主线会变得丧失了主线的意义(因为它太单薄了,很多工作根本没反应上来).
+
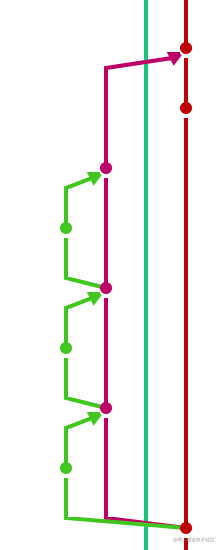
+
+
+
+
+
+
+比如这里,本来左数第二条玫红色的才是主线,因为不规范地在master上直接提交了一次commit并且采用merge方式的pull做了合并导致主线被抬升到了外层.而这次不规范的commit却成了主线.
+
+### git rebase -i
+
+使用这条命令可以修改分支的记录,比如觉得之前的commit修改内容不够单元化,像是`修改了文案1为文案2`,`修改了文案2为文案3`,这种记录对于master分支来说是没必要关注的信息,最好通过`git commit --amend`或者rebase的方式修改掉.
+
+不过并不推荐在提交之前手动做一次整个分支的squash,如果是rebase方式合并的话,也许更有意义.工蜂(腾讯内部的code平台)提供了merge request的标题和内容功能,所以没必要做squash,完全可以不必太聚合,以便反应真实的信息.
+
+为了不影响别人,只用它修改未push的commit,或者如果一条分支只有一个人,你也可以修改已经push的commit.
+
+对于这条命令的更多功能,可以再去查阅其他文章.
+
+## 可读的graph应该长什么样?
+
+先说一个原则,看graph要先看主线,主线要清晰,再看分叉上信息,这与我们的工作流程是一致的.
+
+
+
+
+
+
+
+绿色的hotfix或者feature分支每次不是只允许提交一次commit,只是这一段都是一些小更改.
+
+这看起来有点可笑,一点都不高级.说了这么多做了这么多难道只是为了得到这么简单的图?
+
+没错,`为了让东西变简单,本来就要付出很多代价`,我们所做的就是要让东西变简单,比如努力工作是为了让赚钱变简单,努力提升是为了让工作变简单.让事情变复杂只会让事情不可控.
+
+当然具体如何还是要取决于你采用的git flow,但是原则很简单:
+
+* `每个分叉的子分叉尽量是一个串联一个,内部尽量不要再有自己的提交.`
+
+为什么我认为这样的git graph可读性好,因为它把我们的工作也拍平了,不在乎每个工作的开始时间和持续时间,只关心这个工作的完成时间.
+
+假如一个项目需求1是1月1号启动,2月1号上线,需求2是1月20号启动,2月10号上线.1月10号修了一个bug,2月3号修了一个bug. 听起来是不是很绕?
+
+如果你的git graph显示的也是这样的信息,可读性一定不好,所以我们要做的git graph应该反应的是如下信息:
+
+* 1月10号修补bug
+* 2月1号上线需求1
+* 2月3号修补bug
+* 2月10号上线需求2
+
+## rebase的缺点是什么?
+
+(这里并不讨论rebase可能带来的冲突问题,有很多文章都会讲,上面也已经提到了rebase的危险性,这里只讨论rebase对于git graph的缺点.实际上,冲突只是rebase不恰当使用导致的问题,而非rebase本身的问题.)
+
+当然也有人会说,工作的开始时间也很重要呀,因为它反映了当时工作开展的基础条件.对,这是rebase master的弊端.他让记录清晰,也让记录丢失了一些信息.记录的加工让可读性变得更好,也让信息量变少了.
+
+git rebase 让git graph发生了变化,`每次分叉的检出和并入之间不会再有任何节点`.(因为合并到master采取的是merge行为.否则根本没有分叉)
+
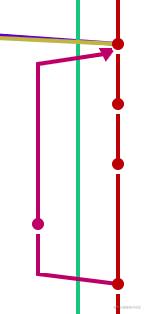
+
+
+
+
+
+
+也就是这种情况不会再出现.因为每次总是`rebase master`,把自己的起点抬了上去.`git rebase实际上让检出信息没有意义,换取了主分支分叉的清晰.`
+
+如果rebase没有缺点,那么也就没有争议.是否使用rebase也要看真实的需求是什么.
+
+## 这篇文章要干什么?
+
+通过rebase让git graph更可读.目的和原则我们都已经说过了,没必要再重新说一遍.
+
+多有谬误之处,还望不吝赐教!